typical Barnaby 01:00 insanity: implementing a patch browser and window manager in #puredata with weeeird semi-documented metaprogramming

typical Barnaby 01:00 insanity: implementing a patch browser and window manager in #puredata with weeeird semi-documented metaprogramming
php-mf2 v0.3.0 is released! This long overdue update contains a variety of bugfixes and new features:
Many thanks to @aaronpk, @diplix, @dissolve, @dymcx @gRegorLove, @jeena, @veganstraightedge and @voxpelli for all your hard work opening issues and sending and merging PRs!
Reasons not to assume everyone uses a traditional green-on-black terminal:

#protip for anyone using QtMultimedia QAudioInput with python’s wave module to write PCM data to a wave file: to convert between QAudioFormat’s sampleSize() number and wave’s sample width number, divide by 8, e.g:
wave_file_to_write.setsampwidth(audio_format.sampleSize() / 8)QAudioFormat’s sampleRate() number works as it is.
Just realised that increasing the dimensions of an element onscreen when it is hovered over creates a “natural”, visual schmitt trigger effect.
Visualising music with a spreadsheet:

EEEEEEVVVIIL genderize.io

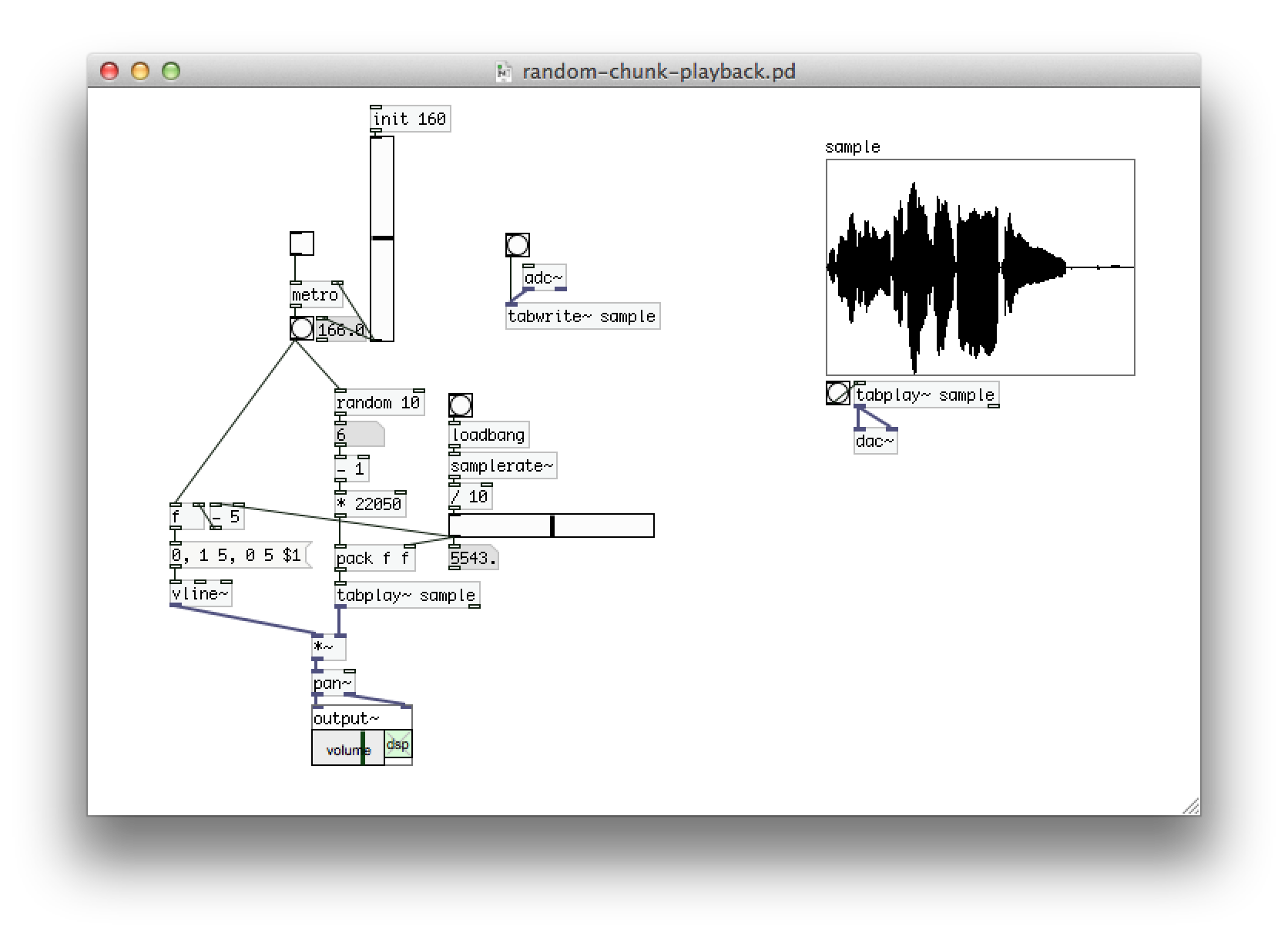
#puredata is so amazing! Recreated one of my favourite @solarference effects in about 20 minutes:
New policy: refuse to make significant changes to systems built under time pressure until they are fully understood, i.e. have been refactored, have good test coverage etc.
@brianloveswords Puredata
Any ideas why the Icelandic locale in #python+natsort doesn’t correctly sort Icelandic characters alphabetically (aábcdðeé etc)? I just implemented a rather awkward hacky way of sorting them using the alphabet and natsort.versorted, but would rather find a way to correct the root issue.
Just released mf2/mf2 v0.2.10! This long-awaited update is all the hard work of @dissolve333 and contains some minor parsing algorithm fixes and support for parsing <area> elements. Thanks Ben!
Python-land: where it’s apparently acceptable for a popular “micro” web application library to not provide a consistent way of accessing raw request data.
I’m looking at you, Flask.
Today’s #django lesson: be VERY careful with programmatic use of contribute_to_class(). It doesn’t overwrite existing fields of the same name, resulting in intriguing errors when the ORM tries to do a SELECT query containing the same columns hundreds of times over…
Ooh, did not know that you could pass an unevaluated #django queryset into an __in query and have subqueries automatically generated: The Django ORM and Subqueries
Finally solved a long-standing problem getting Icelandic characters to work properly in files being downloaded onto Windows machines for use as SPSS syntax. Turns out the solution is to explicitly set the download charset to UTF-8, and to prepend an unnecessary BOM (yuk) to the beginning of the file as so (context: Django view):
import codecs
def export_spss(request):
response = HttpResponse(export_spss(), status=200, mimetype="application/x-spss; charset=utf-8")
response['Content-Disposition'] = 'attachment; filename=syntax.sps'
response.content = codecs.BOM_UTF8 + response.content
return responseWhy is a BOM, which should be completely unnecessary in a UTF-8 file (it has no variable byte order after all) apparently required by some Windows software in order to tell it that the file is UTF-8 encoded, despite Unicode mode being on? Sigh.
Loving Twine: an in-browser nonlinear text adventure creator with HTML export. Effectively a fascinating directed graph UI view over a stateful wiki.
#TIL IE doesn’t upload csv files with text/* media type. Content-type cannot be trusted, the only way of telling if data is of a particular type is to see if it parses successfully.
Today in “things I have typed instead of import”: imprto, improt, implore
I actually quite like how implore pandas looks in my code.
I’m getting too used to #puredata (puredata.info) — I just right-clicked a python class and expected a hypermedia “help” option with params, example usage etc.
Jetbrains PyCharm does have an inline documentation feature, which (when invoked via a complex keyboard “shortcut”), produces this gem:

Even when this feature does work, it shows code “documentation” in a monospace font, typically with no usage example or links to other relevant documentation, as is standard in puredata.
Our tools are inadequate.
Update: added puredata documentation for comparison:

In case it’s not clear from the screenshot, that usage example is live code — it can be interacted with, changed, copied and pasted, played with, experimented with. We typically can’t do that with existing text-based code, let alone mere usage examples.
More thoughts I want to add to this, but I will write them up as a full article.
 a leathery bat
a leathery bat