Today’s late-night puredata madness: creating a 7-limit just intonation abstraction which takes standard 12TET MIDI note numbers and spits the 7-limit just version, expressed as a decimal MIDI note number:
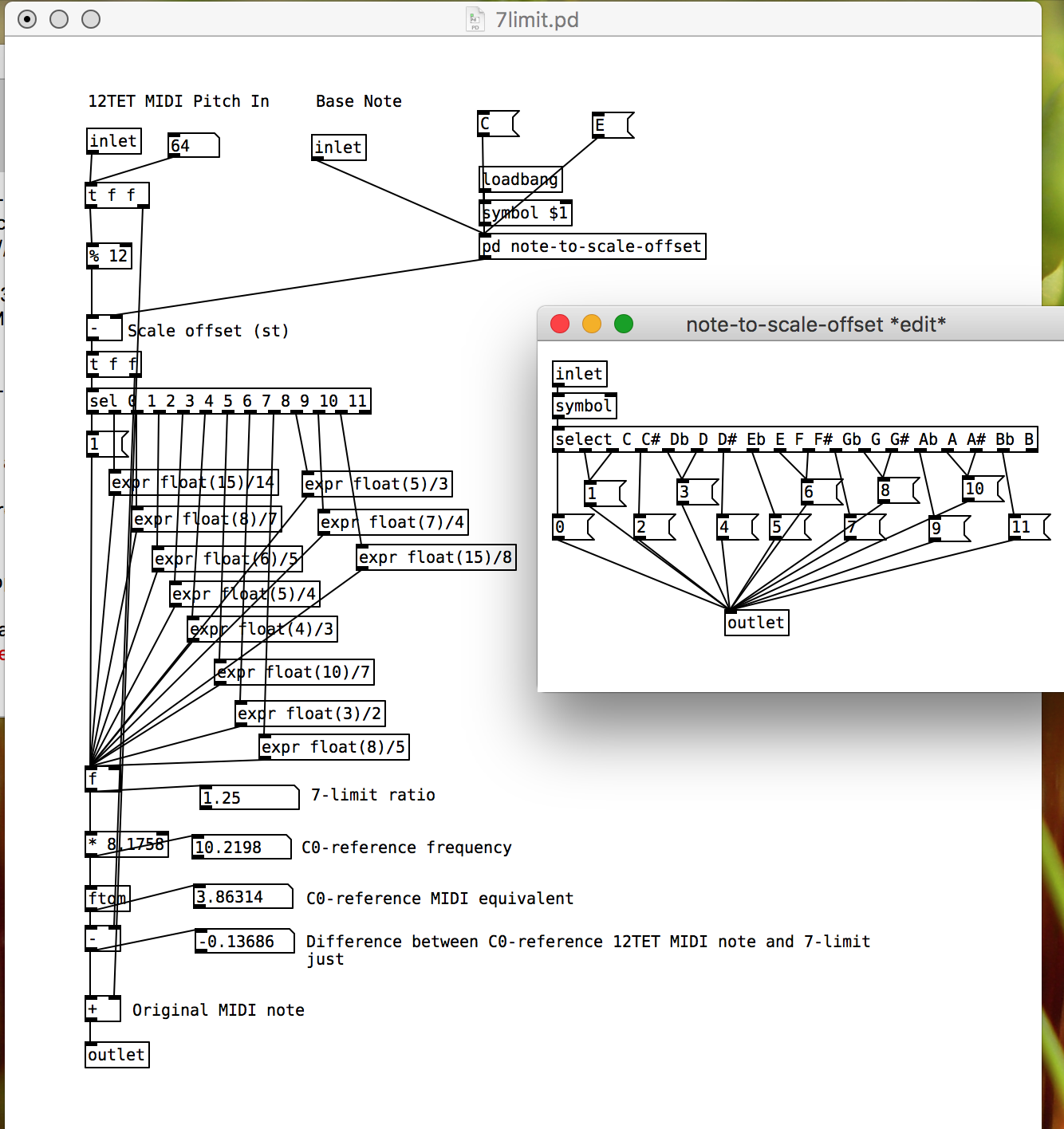
Today’s late-night puredata madness: creating a 7-limit just intonation abstraction which takes standard 12TET MIDI note numbers and spits the 7-limit just version, expressed as a decimal MIDI note number:
Talking of [filterview] (gh), here’s the abstraction I made for it, incorporating stereo smooth filters and a nice mode switching UI made of a [hslider] hidden behind a bunch of canvases.
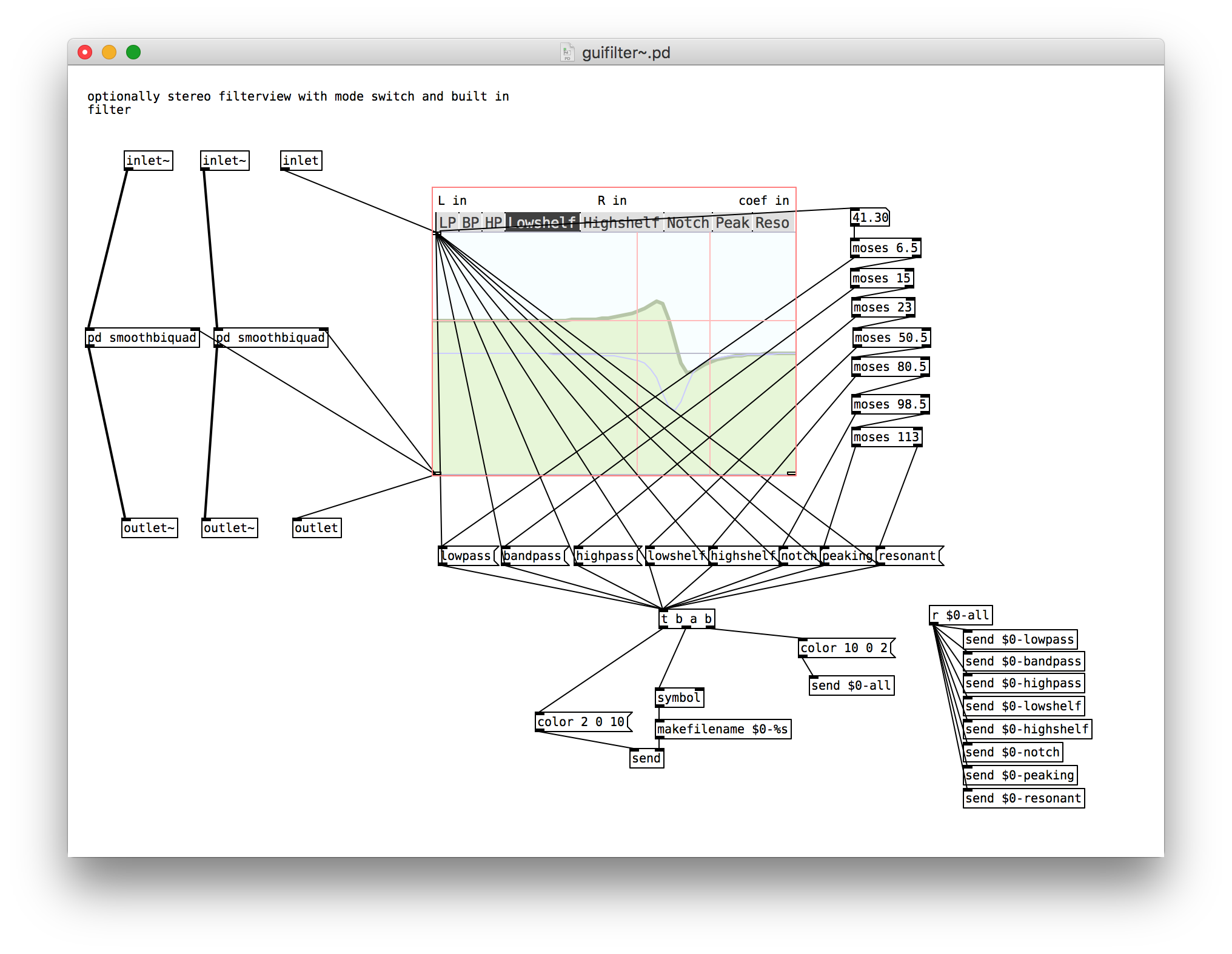
Each canvas has a receive ID of $0- plus the symbol for the relevant filter mode, making the message sending for changing the colours easy.
[biquad~] clicks and pops when changing coefficients, which is annoying when they’re coming from the [filterview] UI. The best way I found of smoothing them was to alternate between two biquad~ objects and crossfade between them over 3ms. This approach, while a little cludgy, is probably generalisable to a lot of similar Pd situations where smooth transitions are desirable.

Software upgrade for the MI Shruthi: Visual Sequencer
One particularly cool feature of the Shruthi is being able to set the mixer mode to seqmix and have the control values in the step sequencer determine which sound sources are active on each step. The problem with this is (or, was!) that, even with the clever binary-based approach for determining how combinations of sound sources map to hexadecimal (0-15) values, it’s incredibly hard to remember the mappings.
I spent an hour or so trawling through the synth code, and documentation for the LCD module, before managing to create a version of the software which, when the mixer operator is set to seqmix, replaces the 0-f step sequencer view with a two-line visual step sequencer, where the four lines from bottom to top represent osc2, osc1, sub and noise*

The controls for the view are exactly the same as before, i.e. pretty unintuitive, but this visualisation of the sequence data makes designing patterns way easier than before.
Here’s the software, as .hex and .syx for flashing or SYSEX dumping:
I originally wanted to have this view all on one line, by creating sixteen custom characters, one representing each combination of sound sources by a bar of pixels. Unfortunately, the HD44780 LCD module only supports eight custom characters, and the Shruthi already defines all of them. I got around this by spreading the display over two lines, reducing the number of characters needed to four, and taking advantage of the “=” default character as the “11” character, and the blank space as the “00” character. I then replaced the two decorative custom characters used on the Shruthi splash screen with single bar characters based on the “=” for “01” and “10”. Finally, in the Editor::DisplayStepSequencerPage function in editor.cc, I made a conditional block based on the state of part.patch().osc[0].option (the non-intuitive location of the mixer operator), displaying the two-line visual view if it’s set to OP_PING_PONG_SEQ.
This is the first of several UI upgrades I plan on making to the Shruthi firmware, depending on how much I can tolerate working on old embedded code in a language I barely know!
*according to the shruthi manual, osc1 and osc2 should be the other way round, but that’s how it ends up working so I accepted it as it is.
typical Barnaby 01:00 insanity: implementing a patch browser and window manager in #puredata with weeeird semi-documented metaprogramming

php-mf2 v0.3.0 is released! This long overdue update contains a variety of bugfixes and new features:
Many thanks to @aaronpk, @diplix, @dissolve, @dymcx @gRegorLove, @jeena, @veganstraightedge and @voxpelli for all your hard work opening issues and sending and merging PRs!
Reasons not to assume everyone uses a traditional green-on-black terminal:

#protip for anyone using QtMultimedia QAudioInput with python’s wave module to write PCM data to a wave file: to convert between QAudioFormat’s sampleSize() number and wave’s sample width number, divide by 8, e.g:
wave_file_to_write.setsampwidth(audio_format.sampleSize() / 8)QAudioFormat’s sampleRate() number works as it is.
Just realised that increasing the dimensions of an element onscreen when it is hovered over creates a “natural”, visual schmitt trigger effect.
Visualising music with a spreadsheet:

EEEEEEVVVIIL genderize.io

#puredata is so amazing! Recreated one of my favourite @solarference effects in about 20 minutes:
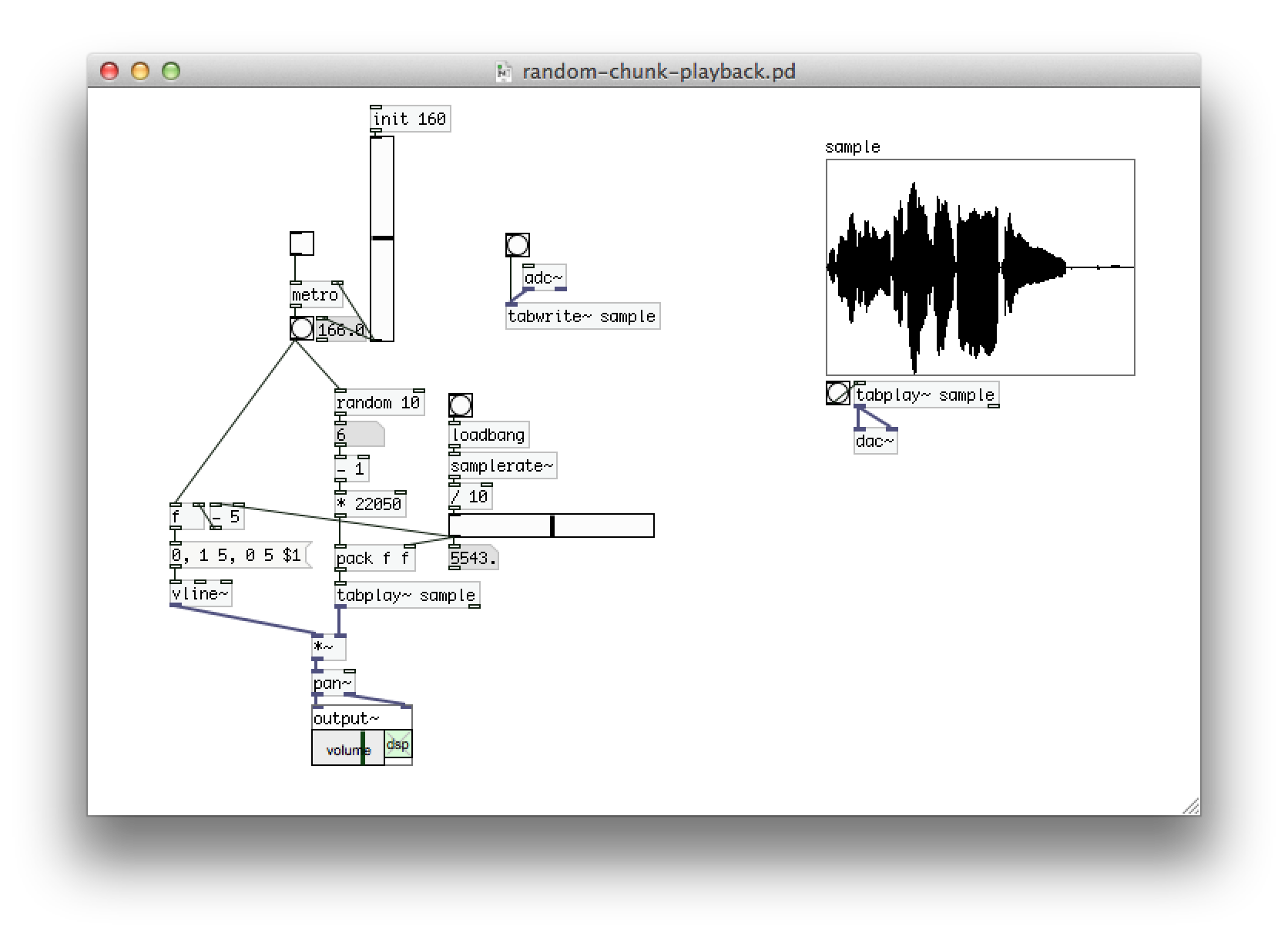
New policy: refuse to make significant changes to systems built under time pressure until they are fully understood, i.e. have been refactored, have good test coverage etc.
@brianloveswords Puredata
Any ideas why the Icelandic locale in #python+natsort doesn’t correctly sort Icelandic characters alphabetically (aábcdðeé etc)? I just implemented a rather awkward hacky way of sorting them using the alphabet and natsort.versorted, but would rather find a way to correct the root issue.
Just released mf2/mf2 v0.2.10! This long-awaited update is all the hard work of @dissolve333 and contains some minor parsing algorithm fixes and support for parsing <area> elements. Thanks Ben!
Python-land: where it’s apparently acceptable for a popular “micro” web application library to not provide a consistent way of accessing raw request data.
I’m looking at you, Flask.
Today’s #django lesson: be VERY careful with programmatic use of contribute_to_class(). It doesn’t overwrite existing fields of the same name, resulting in intriguing errors when the ORM tries to do a SELECT query containing the same columns hundreds of times over…
Ooh, did not know that you could pass an unevaluated #django queryset into an __in query and have subqueries automatically generated: The Django ORM and Subqueries
Finally solved a long-standing problem getting Icelandic characters to work properly in files being downloaded onto Windows machines for use as SPSS syntax. Turns out the solution is to explicitly set the download charset to UTF-8, and to prepend an unnecessary BOM (yuk) to the beginning of the file as so (context: Django view):
import codecs
def export_spss(request):
response = HttpResponse(export_spss(), status=200, mimetype="application/x-spss; charset=utf-8")
response['Content-Disposition'] = 'attachment; filename=syntax.sps'
response.content = codecs.BOM_UTF8 + response.content
return responseWhy is a BOM, which should be completely unnecessary in a UTF-8 file (it has no variable byte order after all) apparently required by some Windows software in order to tell it that the file is UTF-8 encoded, despite Unicode mode being on? Sigh.
 a leathery bat
a leathery bat